My sister became interested in genealogy in the early 1960s. Our paternal grandmother was up in years and yet had kept in touch with many of her relatives. My sister had the foresight to record much of this. She approached our maternal grandparents and asked them for as much as they remembered and wrote this down as well.
For a long time she kept her records in boxes. She kept doing research and adding more information. From time to time I would help her at the libraries around Seattle.
She was an early adopter of Personal Ancestral File and has moved through several programs. Each program and version comes with its own set of problems. My sister's problem has been how to store the information she has collected and document her sources. The GEDCOM file format let her share information with the contacts she has made over the years.
My interests lie more with integrating massive stores of data and making sense of it.
There are many genealogy books all over the world. Unfortunately a lot of it conflicts with each other and lots of errors have been introduced.
I tried my hands at integrating genealogy with a couple of early versions of World Family Tree. The first edition I bought had, maybe, about three disks of family trees people had submitted. A later edition had, I think, fourteen disks of family trees. Many people didn't know birth dates. World Family Free took to adding "WTF est" followed by a date range when no date was given. I spent some time trying to make sense of all of this. The noise was too much. What that computer died so did my interest, at least to the extent of working on it.
Earlier this year, 2013, I decided to try again. I chose Ancestry.com. While it still has the familiar Ancestry Family Trees one can use to acquire information it also has US Census records, state and county marriage and death indexes, and much more. I started by entering my name, my parents' names, and my grandparents' names. From that I could find Family Trees so I started collecting as much as I could. Again I encountered inconsistencies so I backed off and started adding documentation as I went, well at least some times.
It seems people make mistakes and intentionally introduce errors. I understand mistakes. We are humans and humans make mistakes. Intentional errors are another matter. People have changed census records so people's names appear as curse words. Ancestral Trees include fake ancestors. (Unfortunately I've copied some of that into my tree.) Religion has pushed people to document several generations and bind parents together even if it's not the reality of the matter.
Dealing with this raises my stress level. The work is daunting and I've only collected about 6,200 names into my tree. My sister snoops around the web. After finding errors in my tree she shared a backup of her tree with me. It has over 100,000 names in it. She has much more on hardcopy she has yet to enter. Everything I enter comes from the web but in some cases I have selected between alternates based upon her file. I've left some of the stuff that doesn't appear in her file even though some of it may be fake and I may have mistakenly merged unrelated individuals.
It's too much. I have to back off for days and weeks after encountering certain issues in the records. I want to be as accurate as I can and as inclusive as I can. I have other interests and this could easily suck up all my free time.
Sunday, December 29, 2013
Tuesday, December 24, 2013
On translating MatLab syntax to Python syntax
OK, I used to own a copy of MatLab. It's quite expensive. I didn't use it very much. When my computer died that was that. I've used Octave before and for my purposes it's good enough. I like having an IDE so Domain Math IDE works for me as well. See my prior articles for more details.
As far as I'm concerned Python is a much better language. It's more of a full blown programming language. Unfortunately one has to use some extensions to get many of the features built into MatLab or Octave. Fortunately SciPy has done a good job. Rather than rehash stuff provided elsewhere and more comprehensively I will point you to the NumPy package in general and the NumPy for MatLab Users page in particular. The NumPy syntax is a bit more cluncky in a few places but that's more than made up by speed and expanse over Octave. I'll be switching back and forth between the two as I write code for Simulated neural networks.
Enough for now. Review NumPy. It extends what are otherwise scalier functions to apply to arrays and matrices I'll download the CUDA library for Python and test it out this week..
As far as I'm concerned Python is a much better language. It's more of a full blown programming language. Unfortunately one has to use some extensions to get many of the features built into MatLab or Octave. Fortunately SciPy has done a good job. Rather than rehash stuff provided elsewhere and more comprehensively I will point you to the NumPy package in general and the NumPy for MatLab Users page in particular. The NumPy syntax is a bit more cluncky in a few places but that's more than made up by speed and expanse over Octave. I'll be switching back and forth between the two as I write code for Simulated neural networks.
Enough for now. Review NumPy. It extends what are otherwise scalier functions to apply to arrays and matrices I'll download the CUDA library for Python and test it out this week..
Friday, December 20, 2013
Getting the basics of simple Artifical Neural Networks
In my last article I mention I've started playing with Artificial Neural Networks. I bought the book "Tutorial on Neural Systems Modeling" by Thomas J. Anastasio. I've been a bit slow about reading it and applying the lessons learned. I tend to have trouble with mathematics expressed in Greek letters. Likewise, I nod off when dealing with calculus. That being said, I can begin to lay out the framework for the basic computational model he presents.
Anastasio goes on about how floating point numbers represent firing rate in the early models he presents. I don't really care about all that. As far as I'm concerned the models work equally as well no matter what we believe they represent.
So here's the basics: Suppose you want to keep a trace of the activities of your Artificial Neural Network as it changes over time. One could use a matrix where every row represents the value of the neuron as it changes over time and every column represents a particular time. One can model a fully connected network by using a square matrix where each cell in the matrix tells one how strong the connection is between a neuron at time t and either itself or a different neuron at time t+1.

V1, V2,V3, and V4 represents a vertical slice through the trace of the neurons. (t) represents the values at time t and (t+1) represents the values at the next time slice. W represents the Weights, multipliers, between the neurons. W11 is the multiplier connecting V1 to itself. W12 is the multiplier connecting V2 to V1. Etc.
V1(t+1)=W11*V1(t)+W12*V2(t)+W13*V3(t)+W14*V4(t).
V2(t+1)=W21*V1(t)+W22*V2(t)+W23*V3(t)+W24*V4(t).
V3(t+1)=W31*V1(t)+W32*V2(t)+W33*V3(t)+W34*V4(t).
V4(t+1)=W41*V1(t)+W42*V2(t)+W43*V3(t)+W44*V4(t).
The Trace of the neurons can be expressed as the matrix V where the number after the V is converted to an index in an array of simulated neurons. V(1,t) would contain the value of neuron 1 at time t. That V1(t). The weights can also be expressed as the matrix W. W(1,2) would be the matrix version of W12. The set of calculations mentioned above is written in short hand as V(:,t+1)=W*V(:,t) in Matlab.
MatLab starts indicies at 1 where Python starts them at 0. For now I'll start at 1.
An Example using something like MatLab syntax inside English text.
Suppose all of W is 0 except W(2,1)=1, W(3,2)=1, and W(4,3)=1. Suppose all of V is 0 except V(1,1)=1. By iterating t from 1 to 4 and setting V(:,t+1) = W*V(:,t) one finds the following cells have been set to 1: V(2,2), V(3,3), V(4,4). All else remain zero. This "transmission line" behavior will be useful later on.
Input units are clamped to their source so if V(1,t) was an input unit's value at time t then we wouldn't want V(1,t+1) calculated from the weight matrix. We could keep a separate matrix for the weights from the input cells. That would probably be more efficient. For my purposes here I'll leave the weight matrix alone and change the Matrix Vector multiply. If V(1,:) represents an input cell then rather than calculating V(:,t+1):W*V(:,t) the calculation would be V(2:end,t+1)=W(2:end,:)*V(:,t). If V(1,:) represents an input cell and V(4,:) represents and output cell then the calculation would be V(2:end,t+1)=W(2:end,1:end-1)*V(1:end-1,t).
So there you have it. This is the basic layout for the a simple artificial neural net. The weights can be any numbers you want, including imaginary numbers. If you have many input or output neurons then you probably want to split the weight matrix into two matrices. One for the input neurons and another for the internal neurons. Adjust the formulas as needed.
You may wonder why this describes an artificial neural net. I'll leave that until next time.
Anastasio goes on about how floating point numbers represent firing rate in the early models he presents. I don't really care about all that. As far as I'm concerned the models work equally as well no matter what we believe they represent.
So here's the basics: Suppose you want to keep a trace of the activities of your Artificial Neural Network as it changes over time. One could use a matrix where every row represents the value of the neuron as it changes over time and every column represents a particular time. One can model a fully connected network by using a square matrix where each cell in the matrix tells one how strong the connection is between a neuron at time t and either itself or a different neuron at time t+1.
V1, V2,V3, and V4 represents a vertical slice through the trace of the neurons. (t) represents the values at time t and (t+1) represents the values at the next time slice. W represents the Weights, multipliers, between the neurons. W11 is the multiplier connecting V1 to itself. W12 is the multiplier connecting V2 to V1. Etc.
V1(t+1)=W11*V1(t)+W12*V2(t)+W13*V3(t)+W14*V4(t).
V2(t+1)=W21*V1(t)+W22*V2(t)+W23*V3(t)+W24*V4(t).
V3(t+1)=W31*V1(t)+W32*V2(t)+W33*V3(t)+W34*V4(t).
V4(t+1)=W41*V1(t)+W42*V2(t)+W43*V3(t)+W44*V4(t).
The Trace of the neurons can be expressed as the matrix V where the number after the V is converted to an index in an array of simulated neurons. V(1,t) would contain the value of neuron 1 at time t. That V1(t). The weights can also be expressed as the matrix W. W(1,2) would be the matrix version of W12. The set of calculations mentioned above is written in short hand as V(:,t+1)=W*V(:,t) in Matlab.
MatLab starts indicies at 1 where Python starts them at 0. For now I'll start at 1.
An Example using something like MatLab syntax inside English text.
Suppose all of W is 0 except W(2,1)=1, W(3,2)=1, and W(4,3)=1. Suppose all of V is 0 except V(1,1)=1. By iterating t from 1 to 4 and setting V(:,t+1) = W*V(:,t) one finds the following cells have been set to 1: V(2,2), V(3,3), V(4,4). All else remain zero. This "transmission line" behavior will be useful later on.
Input units are clamped to their source so if V(1,t) was an input unit's value at time t then we wouldn't want V(1,t+1) calculated from the weight matrix. We could keep a separate matrix for the weights from the input cells. That would probably be more efficient. For my purposes here I'll leave the weight matrix alone and change the Matrix Vector multiply. If V(1,:) represents an input cell then rather than calculating V(:,t+1):W*V(:,t) the calculation would be V(2:end,t+1)=W(2:end,:)*V(:,t). If V(1,:) represents an input cell and V(4,:) represents and output cell then the calculation would be V(2:end,t+1)=W(2:end,1:end-1)*V(1:end-1,t).
So there you have it. This is the basic layout for the a simple artificial neural net. The weights can be any numbers you want, including imaginary numbers. If you have many input or output neurons then you probably want to split the weight matrix into two matrices. One for the input neurons and another for the internal neurons. Adjust the formulas as needed.
You may wonder why this describes an artificial neural net. I'll leave that until next time.
Tuesday, December 17, 2013
Haven't posted anything in awhile. Trying to play with Artificial Neural Nets.
OK, I mostly skim text books. This isn't always the best approach. I kept looking for the program code in the book I'm reading. It appears that after chapter 2 the reader is suppose to create the program and source the routines. I'll have to do that now to prove to myself I know how to build a Hopfield Network and train it using a single pass through all the patterns. I'll present the code and a sample walk-through when I do. I scanned the material years ago but my machine wasn't up to the challenge to run the code presented. Times have changed. Maybe I can finally get something running and be able to test the limits of current home technology. Learning the CUDA routines for Python should help exploit the NVIDIA video cards for other purposes. I can get a gforce 690 for about $1000. Prices should drop.
Monday, November 18, 2013
I was wrong, matplotlib isn't gnuplot.
Upon review gnuplot, used by octave, just isn't up to the same quality as matplotlib, used by python. The similarity is due to both trying to easily port code from MatLab. Here's equivalent python code to the code I produced in "gnuplot, octave, and python":
It produces this much nicer plot:
 I didn't know about the title function when I did the octave plot. There is plenty of room for the xlabel on the second subplot. There are a couple of small differences in behavior and syntax. The text function seems to position differently, maybe bottom right coordinates in matplotlib as opposed to upper left in gnuplot.
I didn't know about the title function when I did the octave plot. There is plenty of room for the xlabel on the second subplot. There are a couple of small differences in behavior and syntax. The text function seems to position differently, maybe bottom right coordinates in matplotlib as opposed to upper left in gnuplot.
I think this accounts for the xlabel bug in gnuplot. The same "fontsize" is smaller relative to the plot in matplotlib than in gnuplot.
In addition to syntactic differences there are behavioral differences. I'm going to have to study matplotlib's event handling.
On a side note... I tried to reproduce the matplotlib histogram example in octave. I got a stack overflow error when trying to create an array of 10,000 random numbers where numpy had no problem. Maybe octave has some module I need to add. Even producing a histogram of 1,000 random numbers took quite a bit of time in octave. I'm almost ready to buy MatLab again just for the "Computational Neuroscience" course. I have trouble with trial versions of software because they leave bad things on one's computer to prevent you from just reinstalling it after the trial period has run out. These things can interfere with normal installation later on.
import numpy as np
import matplotlib.pyplot as plt
plt.figure(1)
plt.clf
x=np.arange(-10.,10.1,0.1)
plt.subplot(2,1,1)
plt.plot(x,np.sin(x))
plt.xlabel('x',fontsize=12)
plt.ylabel('Sin(x)',fontsize=12)
plt.text(-12.3,1,'(1)',fontsize=12)
plt.title('Text Positioning',fontsize=16)
plt.subplot(2,1,2)
plt.plot(x,2 * np.sin(x))
plt.xlabel('x',fontsize=12)
plt.ylabel('2 * Sin(x)',fontsize=12)
plt.text(-12.3,2,'(2)',fontsize=12)
plt.show()It produces this much nicer plot:
I think this accounts for the xlabel bug in gnuplot. The same "fontsize" is smaller relative to the plot in matplotlib than in gnuplot.
In addition to syntactic differences there are behavioral differences. I'm going to have to study matplotlib's event handling.
On a side note... I tried to reproduce the matplotlib histogram example in octave. I got a stack overflow error when trying to create an array of 10,000 random numbers where numpy had no problem. Maybe octave has some module I need to add. Even producing a histogram of 1,000 random numbers took quite a bit of time in octave. I'm almost ready to buy MatLab again just for the "Computational Neuroscience" course. I have trouble with trial versions of software because they leave bad things on one's computer to prevent you from just reinstalling it after the trial period has run out. These things can interfere with normal installation later on.
Saturday, November 16, 2013
gnuplot, octave, and python
Both Octave and Python use gnuplot to produce graphs. I don't know why I've stayed away from graphs for so long. They're really quite simple to produce. Since I'm trying to relearn Octave right now I'm going to show a couple of issues with Octave's implementation. It might be a problem with gnuplot, I'll do some testing this afternoon. I only have a few minutes right now so here goes.
This code:
produces this graph:
 Notice the text at (-13,1)? It is positioned based upon the coordinate system used for the plot. Unless you adjust for this you're going to get bad results like I've shown here. Fontsize isn't affected so getting the position correct can be complicated if one doesn't use some tricks. I'll be doing some tests this afternoon to see if I can turn hold on and build the plot using one axis setting and position the text using another. I'll let you know what I find.
Notice the text at (-13,1)? It is positioned based upon the coordinate system used for the plot. Unless you adjust for this you're going to get bad results like I've shown here. Fontsize isn't affected so getting the position correct can be complicated if one doesn't use some tricks. I'll be doing some tests this afternoon to see if I can turn hold on and build the plot using one axis setting and position the text using another. I'll let you know what I find.
The second issue is the xlabel on the second subplot. For some reason it gets chopped off. There may be quite a few details one will need to remember to produce nice plots. One might want to build a library of sample plots so the code to produce them is kept handy.
This code:
figure(1)
clf
x=-10:0.1:10;
subplot(2,1,1)
plot(x,sin(x))
xlabel('x','fontsize',12)
ylabel('Sin(x)','fontsize',12)
text(-13,1,'(1)','fontsize',12)
subplot(2,1,2)
plot(x,2 * sin(x))
xlabel('x','fontsize',12)
ylabel('2 * Sin(x)','fontsize',12)
text(-13,1,'(2)','fontsize',12)
produces this graph:
The second issue is the xlabel on the second subplot. For some reason it gets chopped off. There may be quite a few details one will need to remember to produce nice plots. One might want to build a library of sample plots so the code to produce them is kept handy.
Thursday, November 14, 2013
Making DomainMath IDE work without errors
OK, there is something wrong with the auto-loading of packages. I followed these instructions from http://wiki.octave.org/Octave_for_Windows
It didn't work. Java still wasn't loaded. I ended up modifying C:\Software\Octave-3.6.4\share\octave\site\m\startup\octaverc. I added the line
This did the trick. Now the tool bar works and I'm not getting the error about javaaddpath not being implemented. I'm not sure why the rebuild with the -auto option didn't work.
It looks like I'm ready to start mucking about with the plots generated by gnuplot as opposed to how I presume the results look in MatLab based upon the commands in the samples from the book I'm reading.
Small steps.
pkg rebuild -auto
pkg rebuild -noauto ad windows
pkg rebuild -noauto nan % shadows many statistics functions
pkg rebuild -noauto gsl % shadows some core functions
pkg rebuild -auto javaIt didn't work. Java still wasn't loaded. I ended up modifying C:\Software\Octave-3.6.4\share\octave\site\m\startup\octaverc. I added the line
pkg load javaThis did the trick. Now the tool bar works and I'm not getting the error about javaaddpath not being implemented. I'm not sure why the rebuild with the -auto option didn't work.
It looks like I'm ready to start mucking about with the plots generated by gnuplot as opposed to how I presume the results look in MatLab based upon the commands in the samples from the book I'm reading.
Small steps.
Wednesday, November 13, 2013
I bought a microsoft surface pro 2 last weekend.
I like it. It's my first tablet. I'll probably use it for games and e-books. That's an expensive machine just for those features. Who knows. I was thinking I could use it to connect with other computers I need to connect to but SSL VPN doesn't support Win 8.1 yet.
It appears people are attacking my desktop computer in strange ways. I don't want to bounce through it.
This isn't limited to my computers. Someone even tried to write a convenience check against my credit card. I'm finding it hard to be open and secure at the same time.
Maybe the cloud is the way to go. It seems like a security issue to me but then most of my work leaves my desktop functionally acting like a thin client. Plus, I don't know what I really own if it isn't on my hardware. Now my MS Office suite is a one year license. I guess it's all about cash flow.
Anyway, the Surface is a bit heavy at two pounds. It seems light to me compared to the books I read. I'll learn to adjust to the new reading style. I'll both miss having the books around and enjoy not having to deal with them.
It appears people are attacking my desktop computer in strange ways. I don't want to bounce through it.
This isn't limited to my computers. Someone even tried to write a convenience check against my credit card. I'm finding it hard to be open and secure at the same time.
Maybe the cloud is the way to go. It seems like a security issue to me but then most of my work leaves my desktop functionally acting like a thin client. Plus, I don't know what I really own if it isn't on my hardware. Now my MS Office suite is a one year license. I guess it's all about cash flow.
Anyway, the Surface is a bit heavy at two pounds. It seems light to me compared to the books I read. I'll learn to adjust to the new reading style. I'll both miss having the books around and enjoy not having to deal with them.
Sunday, November 10, 2013
Computational Neuroscience and Octave.
Early next year I will be taking the Coursera course "Computational Neuroscience. Rather than using Python it will use MatLab. MatLab is an expensive product. I have an old copy of it on the computer that died about a month ago. I bought MatLab because I got tired of running Octave in line mode on top of Cygwin. I didn't want to buy MatLab again just for this one course so I gave Octave another look.
Octave still has the same look and feel I remember but now there is a GUI wrapper for it. DomainMath IDE provides that wrapper. My few minutes with it so far looks promising even though it has a few quirks I haven't figured out yet. DomainMath IDE is a Java project so you will need to have Java running. I've running Java version 7 update 45. I installed Octave in its default directory then I put the DomainMathIDE_v0.1.5.7z file in the same directory and unzipped it using WinRAR. DomainMathIDE.jar comes up and seems to work just fine even though right now I'm getting the error: "'javaaddpath' undefined". I'll track this down sooner or later. While I installed the java library when I installed Octave it appears I don't have it registered quite right. I haven't been able to make DomainMath IDE the default editor for .m files or even right click on the files and edit them with DomainMath IDE. I can live with this for now.
WinRAR is worth the $29. It handles all the strange compression formats I've run across so far. Maybe 7-zip would work as well. It certainly would work on DomainMathIDE_v0.1.5.7z.
I bought Tutorial on Neural Systems Modeling so I could get up to speed before class begins. It turns out it is one of the suggested books for the class. The website has the source files for the "MATLAB BOXes". That's certainly easier if you don't need to type code to learn from it. There are plenty of exercises to get you head into the material. It doesn't cover cable theory so it looks like I'll be exploring point neuron models for now where spike rate is modeled by a number rather than spikes. I can live with this an learn. Later I can move to more realistic models when I'm investigating aspects this model doesn't cover. For now it's the Rosenblatt model, the Perceptron or a variation of it.
Octave still has the same look and feel I remember but now there is a GUI wrapper for it. DomainMath IDE provides that wrapper. My few minutes with it so far looks promising even though it has a few quirks I haven't figured out yet. DomainMath IDE is a Java project so you will need to have Java running. I've running Java version 7 update 45. I installed Octave in its default directory then I put the DomainMathIDE_v0.1.5.7z file in the same directory and unzipped it using WinRAR. DomainMathIDE.jar comes up and seems to work just fine even though right now I'm getting the error: "'javaaddpath' undefined". I'll track this down sooner or later. While I installed the java library when I installed Octave it appears I don't have it registered quite right. I haven't been able to make DomainMath IDE the default editor for .m files or even right click on the files and edit them with DomainMath IDE. I can live with this for now.
WinRAR is worth the $29. It handles all the strange compression formats I've run across so far. Maybe 7-zip would work as well. It certainly would work on DomainMathIDE_v0.1.5.7z.
I bought Tutorial on Neural Systems Modeling so I could get up to speed before class begins. It turns out it is one of the suggested books for the class. The website has the source files for the "MATLAB BOXes". That's certainly easier if you don't need to type code to learn from it. There are plenty of exercises to get you head into the material. It doesn't cover cable theory so it looks like I'll be exploring point neuron models for now where spike rate is modeled by a number rather than spikes. I can live with this an learn. Later I can move to more realistic models when I'm investigating aspects this model doesn't cover. For now it's the Rosenblatt model, the Perceptron or a variation of it.
Thursday, October 10, 2013
I may just be in a bad mood.
I don't know why people turn simple problems into hard problems.
About a week ago last Monday I fell asleep watching TV. When I woke up the power was out. The following morning when I went to turn on my computer it wouldn't turn on. This is my second computer on an APC UPC to die from what I guess was a power surge. OK, that's fine. Some things happen.
In 2012 I bought a developers version of SQL2012. It wouldn't install on my computer no matter how much I tried to get it installed. I think a trial version of 2008 had left something in the registry or on disk or somewhere so that no matter what I did 2012 wouldn't install. I bought a new faster computer, an i7-3770 processor with 8GB high speed memory. Unfortunately the video processor was slower than on my old machine so I didn't want to use it for gaming (5.1 subscore as opposed to 5.7 on my older machine.) After I did what I wanted to do I let the machine sit, collecting dust.
So when my computer died and I had time, a week ago this Saturday I moved my "new" machine over to my primary workstation and started bringing up to speed. The first problem I encountered was Trend Micro complaining about my virus scanning subscription being out of service and asking me if I wanted to renew. Of course I wanted to be protected so I went on the Best Buy site via the popup and renewed my subscription. After I did what I needed it asked me again. I thought it was
just more steps in completing my subscription but it was the subscription for a computer I gave my parents but they are no longer using. Even so, after saying I had renewed the software said I wasn't protected because my card was accepted.
I called Best Buy. I tried to explain the problem to them. I didn't want to pay for a one year extension to April 2015 for virus scan on a computer that won't be on network under my name ever again and I wanted the subscription I had paid for to be activated. After an hour or so of being shuffled around I ended up with the Geek squad. He said he could take care of the virus software but I'd need to talk with an account executive about getting the extra subscription removed. I had a meeting with my sister so after making sure everything was going to be handled I walked away while they had remote control of my computer.
When I returned I found out they had installed a trial version of the software. I reviewed my bank account and didn't find the payment so I waited until the next day, I was trying to get all of the software in place so I could do my "Computation investing" homework. OK, the next day my bank account had the cost of one subscription taken from it.
This evening I called Best Buy again after verifying the purchases on their website. I said I needed the serial number for Trend Micro because they had removed it from my computer when they replaced the software with a trial version. After some discussion they gave me the serial number for the subscription I purchased on Oct 6th. The serial number wouldn't work. After being bounced to the Geek squad again I was told the problem I didn't have the correct version of the software on my machine.
After they installed the correct version I noticed the expiration date is 9/27/2014. I asked why a one year subscription purchased on 10/6/2013 expired on 9/27/2014 and was told that was because my original subscription started on 9/30/2012. OK, my subscription hasn't been valid since 9/?/2013. If it wasn't valid then why was my 10/6/2013 subscription wasn't valid then why is it counted in the 1 year subscription? I don't get why a one year subscription staring on 9/30/2012 with one year extension would end on 9/27/2014. This is a bit like penny shaving for copper. Maybe one day a year isn't worth my time and effort but for them it means getting paid for 365 years subscription while only providing 364.
Yes, I'm stressed by issues at work where a promise was made yesterday so my customers would get supported after the upgrade of major software but now are not, a loss of, by their figures, about 80,000 hours of labor where this could be resolved by at most 10 hours of labor but they claim a major upgrade is a good time to move to best practices. My DBA supports them and may have instigated this turn of events. It's my employer's business. I just don't like all the noise.
I can't finish my Computational Investing class when I need to spend my evenings decompressing and preparing for another upgrade in another department where they've decided they didn't want to support the computer I had my employer buy a couple of years ago to support the volume and timeliness of data transfer from their system to ours. It turns out they have a 5 day month end freeze on the shared computer they are moving me to even though we have a 24 hour deliver SLA. Even so the data processing is in best case twice as long as current. It's too much noise.
About a week ago last Monday I fell asleep watching TV. When I woke up the power was out. The following morning when I went to turn on my computer it wouldn't turn on. This is my second computer on an APC UPC to die from what I guess was a power surge. OK, that's fine. Some things happen.
In 2012 I bought a developers version of SQL2012. It wouldn't install on my computer no matter how much I tried to get it installed. I think a trial version of 2008 had left something in the registry or on disk or somewhere so that no matter what I did 2012 wouldn't install. I bought a new faster computer, an i7-3770 processor with 8GB high speed memory. Unfortunately the video processor was slower than on my old machine so I didn't want to use it for gaming (5.1 subscore as opposed to 5.7 on my older machine.) After I did what I wanted to do I let the machine sit, collecting dust.
So when my computer died and I had time, a week ago this Saturday I moved my "new" machine over to my primary workstation and started bringing up to speed. The first problem I encountered was Trend Micro complaining about my virus scanning subscription being out of service and asking me if I wanted to renew. Of course I wanted to be protected so I went on the Best Buy site via the popup and renewed my subscription. After I did what I needed it asked me again. I thought it was
just more steps in completing my subscription but it was the subscription for a computer I gave my parents but they are no longer using. Even so, after saying I had renewed the software said I wasn't protected because my card was accepted.
I called Best Buy. I tried to explain the problem to them. I didn't want to pay for a one year extension to April 2015 for virus scan on a computer that won't be on network under my name ever again and I wanted the subscription I had paid for to be activated. After an hour or so of being shuffled around I ended up with the Geek squad. He said he could take care of the virus software but I'd need to talk with an account executive about getting the extra subscription removed. I had a meeting with my sister so after making sure everything was going to be handled I walked away while they had remote control of my computer.
When I returned I found out they had installed a trial version of the software. I reviewed my bank account and didn't find the payment so I waited until the next day, I was trying to get all of the software in place so I could do my "Computation investing" homework. OK, the next day my bank account had the cost of one subscription taken from it.
This evening I called Best Buy again after verifying the purchases on their website. I said I needed the serial number for Trend Micro because they had removed it from my computer when they replaced the software with a trial version. After some discussion they gave me the serial number for the subscription I purchased on Oct 6th. The serial number wouldn't work. After being bounced to the Geek squad again I was told the problem I didn't have the correct version of the software on my machine.
After they installed the correct version I noticed the expiration date is 9/27/2014. I asked why a one year subscription purchased on 10/6/2013 expired on 9/27/2014 and was told that was because my original subscription started on 9/30/2012. OK, my subscription hasn't been valid since 9/?/2013. If it wasn't valid then why was my 10/6/2013 subscription wasn't valid then why is it counted in the 1 year subscription? I don't get why a one year subscription staring on 9/30/2012 with one year extension would end on 9/27/2014. This is a bit like penny shaving for copper. Maybe one day a year isn't worth my time and effort but for them it means getting paid for 365 years subscription while only providing 364.
Yes, I'm stressed by issues at work where a promise was made yesterday so my customers would get supported after the upgrade of major software but now are not, a loss of, by their figures, about 80,000 hours of labor where this could be resolved by at most 10 hours of labor but they claim a major upgrade is a good time to move to best practices. My DBA supports them and may have instigated this turn of events. It's my employer's business. I just don't like all the noise.
I can't finish my Computational Investing class when I need to spend my evenings decompressing and preparing for another upgrade in another department where they've decided they didn't want to support the computer I had my employer buy a couple of years ago to support the volume and timeliness of data transfer from their system to ours. It turns out they have a 5 day month end freeze on the shared computer they are moving me to even though we have a 24 hour deliver SLA. Even so the data processing is in best case twice as long as current. It's too much noise.
Sunday, October 6, 2013
Getting new machine configured for "Computational Investing"
I'm under a bit more stress than I'd like. A lot depends upon me at work and there is little time. These minor annoyances don't help. I end up stalling when things don't go smoothly. None the less I learn quite a bit every time I have to deal with this stuff. This time around I learned I need to learn how python modules are normally installed.
I was lucky that WinRAR lets me install the software on a new machine using the same key. I'd have bought a new copy had I intended to use it on my old machine again. I don't want to take advantage of the company, especially when I like their product. It turns out the exe files mentioned below are auto-extract libraries. They can be explored with WinRAR. I'll probably look this a bit more when I get the time.
I thought I'd go ahead and upgrade the packages to the latest versions. It turns out I'm not up to speed yet so I have to rely upon the exe files. Several of the packages have new versions but I don't know how to install them. Rather than learn how to install and compile packages from zipped tar balls I used the most recent version existing as an exe file. My old machine was old enough that the dot net 1.1 dll was registered. My "new" machine is still old enough to be Win 7 but not so old that it had
msvcr71.dll registered. I found it in another directory and copied it to the setup directory I used to build the QSTK stack for the "Computational Investing" class. While installing pyparsing I got a couple of errors about not being able to register something. I played around a bit then pressed on. It didn't matter.
Here's the files I installed in the order I installed them:
I was lucky that WinRAR lets me install the software on a new machine using the same key. I'd have bought a new copy had I intended to use it on my old machine again. I don't want to take advantage of the company, especially when I like their product. It turns out the exe files mentioned below are auto-extract libraries. They can be explored with WinRAR. I'll probably look this a bit more when I get the time.
I thought I'd go ahead and upgrade the packages to the latest versions. It turns out I'm not up to speed yet so I have to rely upon the exe files. Several of the packages have new versions but I don't know how to install them. Rather than learn how to install and compile packages from zipped tar balls I used the most recent version existing as an exe file. My old machine was old enough that the dot net 1.1 dll was registered. My "new" machine is still old enough to be Win 7 but not so old that it had
msvcr71.dll registered. I found it in another directory and copied it to the setup directory I used to build the QSTK stack for the "Computational Investing" class. While installing pyparsing I got a couple of errors about not being able to register something. I played around a bit then pressed on. It didn't matter.
Here's the files I installed in the order I installed them:
Python 2.7.5
python-2.7.5.msi
numpy
numpy-1.7.1.win32-py2.7.exe
scipy
scipy-0.12.0-win32-superpack-python2.7.exe
dateutil
python-dateutil-1.5.win32.exe
pyparsing
pyparsing-2.0.1.win32-py2.7.exe
matplotlib
matplotlib-1.3.0.win32-py2.7.exe
pandas
pandas-0.12.0.win32-py2.7.exe
setuptools
setuptools-0.6c11.win32-py2.7.exe
cvxopt
cvxopt-1.1.4.win32-py2.7.exe
scikit-learn
scikit-learn-0.14.1.win32-py2.7.exe
scikit-statsmodel
statsmodels-0.5.0.win32-py2.7.exe
qstk
QSTK-0.2.6.win32.exe
Saturday, October 5, 2013
Computer dies, no shared backup
Well, my computer died last Monday evening. I was delaying HW3 on "Computational Investing, Part 1". I had completed the framework and was ready to begin testing. I went down to watch some TV. When I woke up the power was off. The next morning I tried to turn on my computer but it wouldn't turn on. I didn't have time to work on setting up my secondary computer. I hadn't turned it on for about a year. I began setting it up this morning but wanted my virus software enabled before I did much. I followed the instruction and it lead me to best buy where I paid for the subscription then it lead me to a second page and it looked like another step in the process but it was for an extension of the subscription for my parents but they don't have a computer any more. I called best buy to get this handled and after getting bounced around and a couple of hours it looked like it was going to get handled. I had to leave. When I returned Trend Micro had installed a trial version. So here I am having just paid for the subscription renewal and for a second subscription renewal for a copy I didn't want (good through April 2015) and I have a trial version good for 30 days on my machine.
Well, I've got to reinstall a bunch of software and get my "Comp Investing" homework done so I'm not going to be very happy when I get to work on Monday and have to deal with more computer problems. Ah well. I'm glad I documented the installation of the "Comp Investing" software on my blog. I'll go back and find it and update to the latest versions as I do. When I do I'll provide an updated version. At least I have SQL Server installed on this machine where I couldn't get it installed on my other machine. This machine is faster but has slower graphics. I may have to do something about that.
Well, I've got to reinstall a bunch of software and get my "Comp Investing" homework done so I'm not going to be very happy when I get to work on Monday and have to deal with more computer problems. Ah well. I'm glad I documented the installation of the "Comp Investing" software on my blog. I'll go back and find it and update to the latest versions as I do. When I do I'll provide an updated version. At least I have SQL Server installed on this machine where I couldn't get it installed on my other machine. This machine is faster but has slower graphics. I may have to do something about that.
Monday, September 2, 2013
Week 2 of Computational Investing Part 1.
I guess I did the hard part of the week 2 homework by installing the software on Saturday. Again, much of the territory isn't new to me. It was nice to review since I'm going to put some of this into practice, or so I hope.
Today I learned a bit more about the QSTK software and the Matplotlib tool. I just copied and pasted the text from The Quant Soft Took Kit Tutorial and could rapidly rebuild the graphs in the demo. Normalizing returns and producing scatter plots are very easy. Since the data is retrieved from Yahoo Finance I'll not give it here. Review the tool if interested. Be polite and save data locally after retrieving it once if you intend to work with it often.
Normalized returns look at the price and change relative to some point in time, that is Price(t)/Price(i) where i is a constant. Most of the time the price is normalized to i=0 and t ranges from 0 to some larger value but one can normalize to a time in the middle of the graph if one likes.
A scatter graph plots the change of two items relative to each other based upon some interval. It shows how correlated the two items are and whether the are positively or negatively correlated. The greater the deviation from the norm the less correlated they are.
Since I'm learning, I won't put in my own thoughts. It's hard enough to suppress them while learning. Once I have a good grasp of the subject matter I'll put my own stamp on it.
Even if you aren't interested in the stock market the NumPy and SciPy pages as well as Matplotlib if you are interested in doing scientific computation and plotting. I wish the "Computing the Matrix" instructor had used Matplotlib rather than his home grown plotting tool. Matplotlib can show a plot in it own window or produce a PDF. It may be able to produce files in other formats, I haven't taken the time to look.
Today I learned a bit more about the QSTK software and the Matplotlib tool. I just copied and pasted the text from The Quant Soft Took Kit Tutorial and could rapidly rebuild the graphs in the demo. Normalizing returns and producing scatter plots are very easy. Since the data is retrieved from Yahoo Finance I'll not give it here. Review the tool if interested. Be polite and save data locally after retrieving it once if you intend to work with it often.
Normalized returns look at the price and change relative to some point in time, that is Price(t)/Price(i) where i is a constant. Most of the time the price is normalized to i=0 and t ranges from 0 to some larger value but one can normalize to a time in the middle of the graph if one likes.
A scatter graph plots the change of two items relative to each other based upon some interval. It shows how correlated the two items are and whether the are positively or negatively correlated. The greater the deviation from the norm the less correlated they are.
Since I'm learning, I won't put in my own thoughts. It's hard enough to suppress them while learning. Once I have a good grasp of the subject matter I'll put my own stamp on it.
Even if you aren't interested in the stock market the NumPy and SciPy pages as well as Matplotlib if you are interested in doing scientific computation and plotting. I wish the "Computing the Matrix" instructor had used Matplotlib rather than his home grown plotting tool. Matplotlib can show a plot in it own window or produce a PDF. It may be able to produce files in other formats, I haven't taken the time to look.
Saturday, August 31, 2013
Starting Coursera course "Computational Investing Part 1"
As I previously mentioned, I ended up dropping "Coding the Matrix". I'll likely try it again in the future. The combination of taking two courses and dealing with some other issues was just too much for me. The structure of the lectures and the focus on vocabulary was just too much for me.
Well, I started "Computational Investing Part 1" today.
I started installing the software early this morning. It turns out, at least for now, I had to remove the 64 bit versions of Python 2.7.5 and 3.3.2. It appears there is a virtual environment program I can use to keep all of the versions I used installed at the same time and the various installers will work fine. I may deal with that next time. For now I have the 32 bit version of Python 2.7.5 installed.
I have anxiety issues. Having to drop "Coding the Matrix" has set me back. I nearly dropped this new course after having so much problem getting the required software loaded. It appears much of the 32 bit software is packaged in an executable installer. The newer stuff is packages in zip files where one runs python from the command line. I don't know. Maintaining so many versions of packages with several installers seems like a lot of work. I guess the newer method won't be so scary one I learn it.
Even people who don't want to learn Python but are interested in the stock market will find the lectures interesting. I already knew most of what was discussed in the Week 1 lectures.
Since I've installed all of the software Week 2 lectures and homework should go pretty quickly tomorrow.
I haven't spent as much time learning Python as I'd like. Here's my sloppy documentation of the software needed for Computational Investing Part 1:
install in this order
Python 2.7.5
numpy
scipy
dateutil
pyparsing
matplotlib
pandas
setuptools
cvxopt
scikit-learn
scikit-statsmodel
qstk
From this set of Files
cvxopt-1.1.4.win32-py2.7.exe
matplotlib-1.3.0.win32-py2.7.exe
numpy-1.7.1.win32-py2.7.exe
pandas-0.12.0.win32-py2.7.exe
pyparsing-2.0.1.win32-py2.7.exe
python-2.7.5.msi
python-dateutil-1.5.win32.exe
QSTK-0.2.6.win32.exe
Readme.py
scikit-learn-0.14.1.win32-py2.7.exe
scipy-0.11.0-win32-superpack-python2.7.exe
setuptools-0.6c11.win32-py2.7.exe
statsmodels-0.5.0.win32-py2.7.exe
Well, I started "Computational Investing Part 1" today.
I started installing the software early this morning. It turns out, at least for now, I had to remove the 64 bit versions of Python 2.7.5 and 3.3.2. It appears there is a virtual environment program I can use to keep all of the versions I used installed at the same time and the various installers will work fine. I may deal with that next time. For now I have the 32 bit version of Python 2.7.5 installed.
I have anxiety issues. Having to drop "Coding the Matrix" has set me back. I nearly dropped this new course after having so much problem getting the required software loaded. It appears much of the 32 bit software is packaged in an executable installer. The newer stuff is packages in zip files where one runs python from the command line. I don't know. Maintaining so many versions of packages with several installers seems like a lot of work. I guess the newer method won't be so scary one I learn it.
Even people who don't want to learn Python but are interested in the stock market will find the lectures interesting. I already knew most of what was discussed in the Week 1 lectures.
Since I've installed all of the software Week 2 lectures and homework should go pretty quickly tomorrow.
I haven't spent as much time learning Python as I'd like. Here's my sloppy documentation of the software needed for Computational Investing Part 1:
install in this order
Python 2.7.5
numpy
scipy
dateutil
pyparsing
matplotlib
pandas
setuptools
cvxopt
scikit-learn
scikit-statsmodel
qstk
From this set of Files
cvxopt-1.1.4.win32-py2.7.exe
matplotlib-1.3.0.win32-py2.7.exe
numpy-1.7.1.win32-py2.7.exe
pandas-0.12.0.win32-py2.7.exe
pyparsing-2.0.1.win32-py2.7.exe
python-2.7.5.msi
python-dateutil-1.5.win32.exe
QSTK-0.2.6.win32.exe
Readme.py
scikit-learn-0.14.1.win32-py2.7.exe
scipy-0.11.0-win32-superpack-python2.7.exe
setuptools-0.6c11.win32-py2.7.exe
statsmodels-0.5.0.win32-py2.7.exe
Friday, August 23, 2013
time off
I had to back away for awhile. I got irritated with "Coding the Matrix". I dropped the course. I have a short term memory problem. I used to have a near eidetic memory with the exception vocabulary. I've lost much of that capability over the years. My memory is still quite good as long as I'm not being asked to memorize vocabulary. "Coding the Matrix" was mostly vocabulary. Even though I would pause the lectures and replay sections several times the presentation didn't work for me. When he would say something like "There are three equivalent definitions for matrix/matrix multiplication..." my mind was already being overtaxed. I need an anchor to control context switching not an item to hold in short term memory. When dealing with matrix/vector multiplication and vector/matrix multiplication he displayed the vector horizontally in both cases so I was suppose to remember there were three equivalent definitions, vectors to the right of a matrix are to be mentally transposed from a row of numbers to a column of numbers, listen for the name of a particular definition, and remember the distinction between equivalent algorithms associated with those names.
Ah well. I'll take the class again some other time and not try to handle two classes at the same time. I'm not sure I will ever learn the distinction between equivalent named algorithms and appropriately construct distinct implementations. I can view algorithms and know they are equivalent. I would write a working solution in minutes then spend hours trying to figure out why it was graded incorrect. Sometimes the problem was the order in which scalier numbers were multiplied, A*B vs B*A. Getting this stuff down will be good for me even though I'd rather spent time applying Markov Chaining Monte Carlo to several domains before the algorithm gets knocked out of my memory. While "Computational Molecular Evolution" was hard, it too introduced lots of new vocabulary, I could absorb it. The instructor had a different approach to vocabulary.
I think I pick up Rosalind in the evenings again. Maybe that will clear my mind so I can come back to MCMC and Bayesian analysis without the echoes from the Matrix class. I have several applications in mind.
Ah well. I'll take the class again some other time and not try to handle two classes at the same time. I'm not sure I will ever learn the distinction between equivalent named algorithms and appropriately construct distinct implementations. I can view algorithms and know they are equivalent. I would write a working solution in minutes then spend hours trying to figure out why it was graded incorrect. Sometimes the problem was the order in which scalier numbers were multiplied, A*B vs B*A. Getting this stuff down will be good for me even though I'd rather spent time applying Markov Chaining Monte Carlo to several domains before the algorithm gets knocked out of my memory. While "Computational Molecular Evolution" was hard, it too introduced lots of new vocabulary, I could absorb it. The instructor had a different approach to vocabulary.
I think I pick up Rosalind in the evenings again. Maybe that will clear my mind so I can come back to MCMC and Bayesian analysis without the echoes from the Matrix class. I have several applications in mind.
Wednesday, August 7, 2013
Wrapping up Computational Molecular Evolution.
Computational Molecular Evolution turned out to be something different than I expected. I'll be finishing the last assignment tomorrow evening. It is a survey class. There was lots of hands on with several programs. Many techniques were discussed. I'll have an easier time getting up to speed the next time I encounter these things but I doubt I could use these programs by myself and get good results. The field is quite in flux. There are lots of good tools out there but they are changing all the time.
In the final assignment RevTrans 1.4 is mentioned to do DNA alignment. RevTrans 2.0 is in beta release now. It converts the DNA sequences into proteins, does the alignment on the proteins, then maps the DNA by codon to the aligned protein. The Center For Biological Sequence Analysis was upgrading their servers. Once I got the sequence I tried saving it to my (virtual) hard disk. The download process failed. I used copy and paste.
While I was told to save the file with the .fasta extension the file produced by RevTrans 1.4 was
the ClustalW multiple alignment format. EBI readseq was able to detect the real format just fine. The rule is let it autoselect. It was also able to write the PHYLIP4 format used by BioPerl.
I guess I am getting a feel for the range of tools available even if I don't know how to use them very well.
In the final assignment RevTrans 1.4 is mentioned to do DNA alignment. RevTrans 2.0 is in beta release now. It converts the DNA sequences into proteins, does the alignment on the proteins, then maps the DNA by codon to the aligned protein. The Center For Biological Sequence Analysis was upgrading their servers. Once I got the sequence I tried saving it to my (virtual) hard disk. The download process failed. I used copy and paste.
While I was told to save the file with the .fasta extension the file produced by RevTrans 1.4 was
the ClustalW multiple alignment format. EBI readseq was able to detect the real format just fine. The rule is let it autoselect. It was also able to write the PHYLIP4 format used by BioPerl.
I guess I am getting a feel for the range of tools available even if I don't know how to use them very well.
Python 101, part 2
If you haven't loaded Python then you need to do that first. Let me know if the instruction I wrote up in Python 101, part 1 are too confusing. I've tried to be pretty thorough.
If you're new to programming don't get too worried. You will get the hang of it quite quickly.
Python can be used like a very strange calculator. When you start python you see something like this:
 The cursor will be one space after the ">>>" characters. These are the command prompt characters.
The cursor will be one space after the ">>>" characters. These are the command prompt characters.
To use python as a calculator one just types the formula after the prompt then press the enter key:
Unlike the normal calculator you probably have around the house, Python follows the math rules of operator precedence. What that means is the multiply and divide operators get executed before the add and subtract operators.
You can tell python you want certain operations to happen first by putting parens (parentheses) around the operations you want done first.
All of this is defined in the Python Tutorial under Using Python as a Calculator. While the manual may seem frightening or confusing at first you get use to these things. Don't read manuals like you would a book. Use the manual like you would a catalog or a web side like BestBuy.com.
Most calculators have MR and MS buttons. These are Memory Recall and Memory Store. Most programming languages let you name storage locations and Python is no exception. If you've looked at the link to Using Python as a Calculator you see these memory stores are call "Variables". In Python you put the variable on the left side of the equal sign(=) and the remember this is just a convention to store the result of a calculation in the named location. You can then recall the value by using its name.
This, and the stuff one gets when one clicks on the "click to expand" text should be enough to solve Rosalind's Variables and Some Arithmetic. I haven't really added much other than a lot of words.
If one was limited to numbers programming languages wouldn't be very interesting.
Strings are covered quite nicely in the Python Tutorial. If it's too much then just stick with the basic string for now and remember the backslash(\) needs to be doubled up in certain cases.
Rosalind suggests using v2.7.5. Version 2 of Python doesn't put parens around what one wants to print. Rosalind covers lists and strings together because strings are handled like lists of characters. There is a never ending battle among programmers concerning zero relative or one relative indexing. Python is zero relative indexing. Python also lets you index a range of items in a list at the same time, just remember that the range starts at the zero relative indexed item and stops one short of the second index. One can "add" one string or list to another using the plus sing(+). Be careful when dealing with lists. Selecting a range returns a list.
I hope this is helping you get started.
If you're new to programming don't get too worried. You will get the hang of it quite quickly.
Python can be used like a very strange calculator. When you start python you see something like this:

To use python as a calculator one just types the formula after the prompt then press the enter key:
>>> 5 + 1
6
>>>
Unlike the normal calculator you probably have around the house, Python follows the math rules of operator precedence. What that means is the multiply and divide operators get executed before the add and subtract operators.
>>> 5 + 1 * 2
7
>>>
You can tell python you want certain operations to happen first by putting parens (parentheses) around the operations you want done first.
>>> (5 + 1) * 2
12
>>>
All of this is defined in the Python Tutorial under Using Python as a Calculator. While the manual may seem frightening or confusing at first you get use to these things. Don't read manuals like you would a book. Use the manual like you would a catalog or a web side like BestBuy.com.
Most calculators have MR and MS buttons. These are Memory Recall and Memory Store. Most programming languages let you name storage locations and Python is no exception. If you've looked at the link to Using Python as a Calculator you see these memory stores are call "Variables". In Python you put the variable on the left side of the equal sign(=) and the remember this is just a convention to store the result of a calculation in the named location. You can then recall the value by using its name.
>>> a = 5 + 1 * 2
>>> a
7
>>>
This, and the stuff one gets when one clicks on the "click to expand" text should be enough to solve Rosalind's Variables and Some Arithmetic. I haven't really added much other than a lot of words.
If one was limited to numbers programming languages wouldn't be very interesting.
Strings are covered quite nicely in the Python Tutorial. If it's too much then just stick with the basic string for now and remember the backslash(\) needs to be doubled up in certain cases.
>>> a
'this\that'
>>> print(a)
this hat
>>> a='this\\that'
>>> print(a)
this\that
>>>
Rosalind suggests using v2.7.5. Version 2 of Python doesn't put parens around what one wants to print. Rosalind covers lists and strings together because strings are handled like lists of characters. There is a never ending battle among programmers concerning zero relative or one relative indexing. Python is zero relative indexing. Python also lets you index a range of items in a list at the same time, just remember that the range starts at the zero relative indexed item and stops one short of the second index. One can "add" one string or list to another using the plus sing(+). Be careful when dealing with lists. Selecting a range returns a list.
>>> a='one rainy day'
>>> a[0]
'o'
>>> a[0:4]+ a[10:]
'one day'
>>> a=['one','rainy','day']
>>> a[2]+' '+a[0]
'day one'
>>> a[1:3]+a[0:1]
['rainy', 'day', 'one']
>>>
I hope this is helping you get started.
Monday, August 5, 2013
Coding the Matrix Lectures vs Assignments
It is probably about learning style. I don't do well in lecture classes. I have trouble with short term memory. By the time I'm done listening to a lecture about two types of matrix-vector multiplication and vector-matrix multiplication I've been vectored into the state of confusion. My lights are out. I find myself reviewing Wikipedia to do the assignments. I've tried going back into the videos and listening to them several times. It doesn't sink in. Mathematicians have a love affair with Greek letters. Just seeing them does something to my mind. It doesn't really matter how many times I'm told about how a vector space can be defined by a span none of this is grounded. I'm hearing word salad. I fear I'm going to have some real trouble ahead. I've been able to get the correct answer to all of the assignments so far. When it came to vector space I ended up doing a Boolean search. On two of the three tasks it took me 4 attempts to get the correct answer to two questions each with the answer to each question being True or False. Four attempts at four possibilities to get the correct one? That's obviously worse than chance.
I really didn't understand vector space.
Here's hoping things get better.
I really didn't understand vector space.
Here's hoping things get better.
Saturday, August 3, 2013
On retrieving protien sequences from online databases.
Getting a FASTA file from the UniProt database is quite simple. I'll need to review the user agreement before I go very far but here's a simple python 2.7.5 routine to get a set of proteins from UniProt based upon the accession IDs
While this could be part of a solution to Rosalind's Finding a Protein Motif there's a bit more to it than that. I tried something similar with the NCBI database using a URL like this:
http://www.ncbi.nlm.nih.gov/protein/238064857?report=fasta&format=text but it doesn't work. NCBI expect you to use their Entrez Utilities. BioPython has its own interface on top of Entrez.
The two websites may have slightly different protein sequences. The header to the sequence for B5ZC00 look like this (I've broken the line so it is easier to read):
The sp prefix indicates SWISS-PROT. The gi prefix indicates GenInfo Integrated Database. Here are the prefixes handled by NCBI. The NCBI header seems to indicate a SWISS-PROT variant of the protein mentioned above. Interestingly http://www.uniprot.org/uniprot/B5ZC00.1.fasta returns a different header with the prefix "UniProtKB/TrEMBL". There's so much to learn and more of it every day. I guess I could put all three into a single file then run a Hamming count on them to see if they differ. Unfortunately I'm using the second field as the name when I build my python structures so I'd have to fudge one of the one's retrieved from the UniProt DB so they would have different names/accession IDs.
import urllib2
def getFromUniprot(filename,accessionList):
"""Get a set of protein sequenses from the UniProt database"""
FastaData=''
for accession in accessionList:
x=urllib2.urlopen('http://www.uniprot.org/uniprot/'+accession+'.fasta')
FastaData+=x.read()
x.close()
f=open(filename,'w')
f.write(FastaData)
f.close
getFromUniprot('mprt.fasta',['A2Z669','B5ZC00',
'P07204_TRBM_HUMAN','P20840_SAG1_YEAST'])
While this could be part of a solution to Rosalind's Finding a Protein Motif there's a bit more to it than that. I tried something similar with the NCBI database using a URL like this:
http://www.ncbi.nlm.nih.gov/protein/238064857?report=fasta&format=text but it doesn't work. NCBI expect you to use their Entrez Utilities. BioPython has its own interface on top of Entrez.
The two websites may have slightly different protein sequences. The header to the sequence for B5ZC00 look like this (I've broken the line so it is easier to read):
UniProt:
>sp|B5ZC00|SYG_UREU1 Glycine--tRNA ligase OS=Ureaplasma urealyticum serovar 10 (strain ATCC 33699 / Western) GN=glyQS PE=3 SV=1
NCBI:
>gi|238064857|sp|B5ZC00.1|SYG_UREU1 RecName: Full=Glycine--tRNA ligase; AltName: Full=Glycyl-tRNA synthetase; Short=GlyRS
The sp prefix indicates SWISS-PROT. The gi prefix indicates GenInfo Integrated Database. Here are the prefixes handled by NCBI. The NCBI header seems to indicate a SWISS-PROT variant of the protein mentioned above. Interestingly http://www.uniprot.org/uniprot/B5ZC00.1.fasta returns a different header with the prefix "UniProtKB/TrEMBL". There's so much to learn and more of it every day. I guess I could put all three into a single file then run a Hamming count on them to see if they differ. Unfortunately I'm using the second field as the name when I build my python structures so I'd have to fudge one of the one's retrieved from the UniProt DB so they would have different names/accession IDs.
Wednesday, July 31, 2013
Computational Molecular Evolution
OK, I trying to do the quiz for Bayesian Analysis. I'm stuck on the first problem. I'm doing the calculations as I understand them but instead of getting fractions for likelihood I'm getting whole numbers. That can't be. I coded:
 as:
as:
I'll figure it out. I thought I did it correctly. Clearly I did not. There is a math function factorial. I was too lazy to import the math library. It seems to me that the number of ways one can get heads from N flips doesn't really express the probability of it.
Ah, I see the problem. That superscript really does mean "Raised to the power". Now I can move on to more misunderstandings on my part.
Interestingly, Wikipedia gives a different but similar function where r is the uniform prior distribution, somewhat analogous to p in the prior formula. The Wikipedia example following this helped me identify my error.
 While I know some about probabilities I hadn't dealt with conditional probabilities. It looks quite powerful and useful.
While I know some about probabilities I hadn't dealt with conditional probabilities. It looks quite powerful and useful.
On another topic. When using Python one needs to know math.log(x) gives the natural log of x rather than the base 10 log of x. The base 10 log of x is math.log10(x).
It gets stranger. math.log1p(x) is the natural log of 1+x.
def fac(n):
if n == 1: return 1
else: return n * fac(n-1)
def prob(h,n,p):
return float((fac(n)*p*(1-p)))/float(fac(h)*fac(n-h))
I'll figure it out. I thought I did it correctly. Clearly I did not. There is a math function factorial. I was too lazy to import the math library. It seems to me that the number of ways one can get heads from N flips doesn't really express the probability of it.
Ah, I see the problem. That superscript really does mean "Raised to the power". Now I can move on to more misunderstandings on my part.
Interestingly, Wikipedia gives a different but similar function where r is the uniform prior distribution, somewhat analogous to p in the prior formula. The Wikipedia example following this helped me identify my error.

On another topic. When using Python one needs to know math.log(x) gives the natural log of x rather than the base 10 log of x. The base 10 log of x is math.log10(x).
It gets stranger. math.log1p(x) is the natural log of 1+x.
Tuesday, July 30, 2013
FoldIt, Protein folding as a game.
FoldIt is the game of folding proteins. I started playing in August 2010. After about a year I took a couple of years off. I started folding again this spring. I guess I'm helping science. I don't know.
Proteins rapidly fold into their natural state once built by Ribosomes. They can be denatured by temperature, PH, or in other ways but once conditions are right they will fold again into the same complex shape. Unfortunately science doesn't have good algorithms to predict their shape from the string of amino acids. The technology is developing rapidly. It has a long ways to go.
The assertion is humans are better at folding than software alone. Humans, using their intuitions, can see problems and adjust. By playing the game, science can build a huge database of moves humans make while folding proteins and use this database to improve the automation. The FoldIt players have scored well in global competition but mostly it's just a hand full of players. I don't know if the rest of us add any value at all. Here I am after about 45 minutes of play. Most of the score came in the first 15 minutes:
 I'm in 94th place in the Global Soloist scoreboard. This shows the problem. While I can tell the protein fold is a mess I'm just learning about the tools available to me. A string of hydrophilic amino acids usually form a helix, In this game the hydrophilic AA have blue side chains and the hydrophobic AA have orange side chains. The hydrophobic AA usually end up in the middle of the protein grouped together and the hydrophilic AA end up on the outside. This puzzle says it's an Integrase. Wikipedia show them folding as a series of helixes. If I had a bunch of time on my hands I'd restructure the protein as a series of helixes and see but I'm just trying to maintain my global position so won't be spending much time. As it turns out there are websites I'll not mention here that will help you categorize a string of amino acids and provide their common motif. Rosalind is helping me learn about these databases and more.
I'm in 94th place in the Global Soloist scoreboard. This shows the problem. While I can tell the protein fold is a mess I'm just learning about the tools available to me. A string of hydrophilic amino acids usually form a helix, In this game the hydrophilic AA have blue side chains and the hydrophobic AA have orange side chains. The hydrophobic AA usually end up in the middle of the protein grouped together and the hydrophilic AA end up on the outside. This puzzle says it's an Integrase. Wikipedia show them folding as a series of helixes. If I had a bunch of time on my hands I'd restructure the protein as a series of helixes and see but I'm just trying to maintain my global position so won't be spending much time. As it turns out there are websites I'll not mention here that will help you categorize a string of amino acids and provide their common motif. Rosalind is helping me learn about these databases and more.
I may have to quite folding for awhile so I can keep up on Coursera and Rosalind.
Proteins rapidly fold into their natural state once built by Ribosomes. They can be denatured by temperature, PH, or in other ways but once conditions are right they will fold again into the same complex shape. Unfortunately science doesn't have good algorithms to predict their shape from the string of amino acids. The technology is developing rapidly. It has a long ways to go.
The assertion is humans are better at folding than software alone. Humans, using their intuitions, can see problems and adjust. By playing the game, science can build a huge database of moves humans make while folding proteins and use this database to improve the automation. The FoldIt players have scored well in global competition but mostly it's just a hand full of players. I don't know if the rest of us add any value at all. Here I am after about 45 minutes of play. Most of the score came in the first 15 minutes:

I may have to quite folding for awhile so I can keep up on Coursera and Rosalind.
Sunday, July 28, 2013
Coding the Matrix -- Yikes, I'm quite behind.
OK, I'm having trouble keeping focused, as usual. I didn't start the class assignments for week 1(zero relative) of Coursera's "Coding the Matrix" until this after noon, about 6PM. It's now 10PM and I'm complete. The Politics lab was interesting. I don't know why I'm so slow at working these problems. I used to be able to handle them quickly. My age must be getting to me. Week 3 says
Now looking back at my work on week 1's assignments I realize I haven't taken advantage of the zip function. I coded:
when I should have coded:
Learning the Python language takes time. I'm not used to thinking this way. I've mostly moved from procedural languages into SQL. This is a step sideways. SSIS is pictorial. One uses functions to get the results one wants. Python is textual.
Week 3 is upon us, and with it we enter the middle third of the course. This week's topic, The Matrix, represents a transition. Most of it is, in a sense, mechanics, but it opens the door to the more math material that comes next.I've got to get moving. At least I've made the due date for week 1. week 4 is out now.
There is a lot of work being assigned this week. If it is possible for you, I suggest you not try to get it all done in a week; take advantage of at least some of the three-week time period you have. Next week's assignment won't be as heavy, so you'll have time to catch up.
Now looking back at my work on week 1's assignments I realize I haven't taken advantage of the zip function. I coded:
[a[x]*b[x] for x in range(len(a))]
when I should have coded:
[x*y for x,y in zip(a,b)]
Learning the Python language takes time. I'm not used to thinking this way. I've mostly moved from procedural languages into SQL. This is a step sideways. SSIS is pictorial. One uses functions to get the results one wants. Python is textual.
Saturday, July 27, 2013
Completing my 32nd problem on Rosalind
I completed my 32nd problem on Rosalind. As is sometimes the case I over-thought the problem. Here's the short of it:
Give a count of nodes in a tree graph and a set of lines connecting particular pairs of nodes, how many additional lines will be needed to connect all of the nodes. So here's the thing, there's really only one way to connect three nodes. Here's the two ways to connect four nodes:
 Count the nodes and count the lines. There's a pattern there. I don't know why I didn't see it. I got bogged down counting the nodes that weren't connected to any other nodes and the sets of connected nodes:
Count the nodes and count the lines. There's a pattern there. I don't know why I didn't see it. I got bogged down counting the nodes that weren't connected to any other nodes and the sets of connected nodes:
 OK, that's 13 nodes, 3 sets of connected nodes and 3 unconnected nodes. Let's see, that's two lines to connect the three sets and three lines to connect the unconnected nodes for 5 lines. That's 13 - 10 connected nodes for 3 unconnected nodes and 3 sets of connected nodes and - 1 because one set counts as the base. 13 - 10 + 3 - 1 = 5. But how many nodes? 13 and how many lines are needed to connect them and how many lines have been defined?
OK, that's 13 nodes, 3 sets of connected nodes and 3 unconnected nodes. Let's see, that's two lines to connect the three sets and three lines to connect the unconnected nodes for 5 lines. That's 13 - 10 connected nodes for 3 unconnected nodes and 3 sets of connected nodes and - 1 because one set counts as the base. 13 - 10 + 3 - 1 = 5. But how many nodes? 13 and how many lines are needed to connect them and how many lines have been defined?
That's as close as I'm going to get to providing the answer to Completing a Tree, my 32nd problem.
Give a count of nodes in a tree graph and a set of lines connecting particular pairs of nodes, how many additional lines will be needed to connect all of the nodes. So here's the thing, there's really only one way to connect three nodes. Here's the two ways to connect four nodes:
That's as close as I'm going to get to providing the answer to Completing a Tree, my 32nd problem.
Thursday, July 25, 2013
On getting started solving Rosalind problems in the Python Village
Rosalind assumes some level of programming skills. Some people may come to the table with none whatsoever. The Python Village moves pretty quick. I'll try to slow it down for those who haven't programmed at all. I'm not going to rehash stuff Rosalind provides directly. For instance, in problem INI2 one sees:
 That's pretty sparse. But that "click to expand" text needs to be clicked most of the time. Even if it doesn't address the particular problem it gives lots of information about why the particular problem is being asked to be solved.
That's pretty sparse. But that "click to expand" text needs to be clicked most of the time. Even if it doesn't address the particular problem it gives lots of information about why the particular problem is being asked to be solved.
 That print command is version 2.x. In 3.x you would use:
That print command is version 2.x. In 3.x you would use:
I don't mind helping people get started. Let me know if I'm being of any help. Otherwise I'll just move on. One last thing...
After you solve a problem buttons for "Solutions" and "Explanation" appear. "Explanation" gives some additional information. People seem more willing to give "Solutions". You will see many ways to solve the same problem.

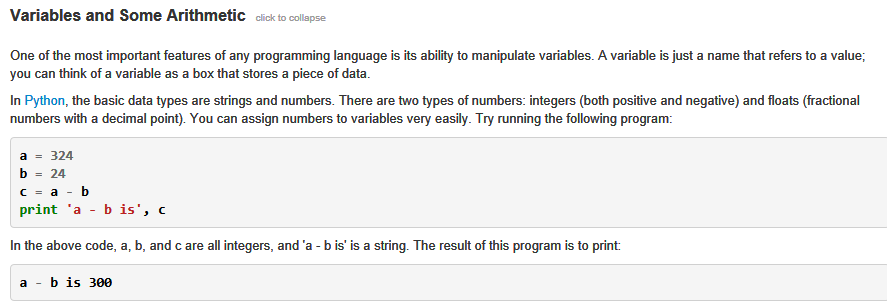
print ('a - b is',c)
I don't mind helping people get started. Let me know if I'm being of any help. Otherwise I'll just move on. One last thing...
After you solve a problem buttons for "Solutions" and "Explanation" appear. "Explanation" gives some additional information. People seem more willing to give "Solutions". You will see many ways to solve the same problem.
Wednesday, July 24, 2013
Always check your work.
I posted a solution to a problem a few days back but my results weren't being accepted. It was quite frustrating. It turned out my posted solution wasn't the routine I was using to generate the results. I must have submitted my results 10 times. I was quite sure I had the correct solution. Finally this evening I reviewed the results I was submitting very closely. The error stuck out like a sore thumb.
Tag me embarrassed. There is confidence then over-confidence. I am humbled by my hubris.
Sorry for posting a working solution to a Rosalind problem and identifying it as such.
I normally produce my results by way of a wrapper routine like this:
Tag me embarrassed. There is confidence then over-confidence. I am humbled by my hubris.
Sorry for posting a working solution to a Rosalind problem and identifying it as such.
I normally produce my results by way of a wrapper routine like this:
def sseqf(filename):
clearBioDb()
loadFASTA(filename)
print ' '.join(map(str,
sseq(namedSeq[namedOrder[0]],
namedSeq[namedOrder[1]])))
I write the actual routine sseq separately. If the output will be of substantial size I will write it to a file rather than print it. I'll discuss join and map in a few days.
Tuesday, July 23, 2013
Python 101, part 1
I was asked to provide some more in depth information about the Rosalind Python Village problems. Rosalind moves pretty quickly though the process. If one knows any computer languages Python will come pretty quickly but if you are new to computer programming all languages may be a bit hard. I'm assuming anyone who want to start programming is willing to do the first step, that is load the software on your computer. Here's the steps:
I hope that gets you set up.
The first time I tried INI1 I didn't do the right thing. I don't know why. It said to type
As it turns out this.py is a module in C:\Python33\Lib for V3.3.2 or in C:\Pythod27\Lib for V2.7.5. You can open these modules in the editor and see what they look like The only difference is the format of the print statement. The small difference in the print statement is one of the few differences between the two versions beginners will notice right away. There are other differences.
When you want to run a module from the shell you type "import " followed by the name of the module then press enter. I haven't tried putting the same module name in my working directory and in the library folder so I don't know what would happen.
While writing this I learned a little bit about Python string constants.
If you haven't played around with string constants try some of these:
Then try some of your own. Have fun. Work Problem INI1 if you haven't done so already.
- go to the Python Download page.
- choose the correct version(s). V3.3.2 is the current version as of this writing but some Python code won't run on V3.3.2 so one might need to get V2.7.5. I have both version installed and use V2.7.5 for Rosalind and V3.3.2 for Computational Molecular Evolution. I haven't run across the need for V2.7.5 yet but that's the version Rosalind's ini1 asks you to load. I'm going to keep it simple but suggest you install both versions.
- Download and Install V2.7.5. Let it use its default file folder. For Windows that's C:\Python27.
- Download and Install V3.3.2. Let it use its default file folder. For Windows that's C:\Python33.
- Create a folder for each project. I have a folder for Rosalind under Documents.
- If the project will be using V2.7.5:
- Find the "IDLE (Python GUI)" Icon in the start menu under "Python 2.7".
- Right click on it and select "Copy".
- Open the projects folder.
- Right Click on the folder's background and select "Paste".
- Right Click on the newly pasted short cut and select "Properties".
- Click on the "Shortcut" tab.
- Change the "Start in: to the fully qualified path of the directory you just created.
- Click on the "OK" button.
I hope that gets you set up.
The first time I tried INI1 I didn't do the right thing. I don't know why. It said to type
import thisin the command line and see what happens. I did that but for some reason I didn't get "Then, click the 'Download dataset' button below and copy the Zen of Python into the space provided." What a mess.
As it turns out this.py is a module in C:\Python33\Lib for V3.3.2 or in C:\Pythod27\Lib for V2.7.5. You can open these modules in the editor and see what they look like The only difference is the format of the print statement. The small difference in the print statement is one of the few differences between the two versions beginners will notice right away. There are other differences.
When you want to run a module from the shell you type "import " followed by the name of the module then press enter. I haven't tried putting the same module name in my working directory and in the library folder so I don't know what would happen.
About String constants.
String constants can be quoted by either single quote(') or double quote(").While writing this I learned a little bit about Python string constants.
If you haven't played around with string constants try some of these:
>>> '' '' '' >>> ' '' ' ' ' >>> " " ' ' >>> " ' " " ' " >>> ' \' ' " ' " >>>
Then try some of your own. Have fun. Work Problem INI1 if you haven't done so already.
Protein Melting temerpature and ancient life.
Yesterday I was introduced to protein melting temperature. Many things can cause a protein to denature(unfold). Temperature is one of those causes. Life needs to have proteins within a certain range below their melting point. I don't know the details right now. The part I found most interesting is how scientists have built clades from DNA sequences then predicted the most likely ancestor sequences then used them to build proteins. From http://news.ufl.edu/2003/09/17/ancientprotein/, a 2003 paper concerning one such reconstruction, one can infer the temperature of the ancestor's habitat. Since that 2003 the field has progressed. It appears this technique maps closely to other techniques for determining world temperature in the distant past.
When introduced to Hamming distance, the number of changes needed to convert one sequence into another, I wrote this simple implementation:
It works and is easily understood. I found this from http://code.activestate.com/recipes/499304-hamming-distance/. I'm not sure I like summing truth values.
I'm learning pretty quickly. There's a lot to learn. I guess once one learns the language the faster code is readable.
Knowing the Hamming distance between a set of DNA, RNA, or AA sequences is the first step to building an un-rooted tree and this is the first step towards reconstructing the most likely ancestor sequences.
When introduced to Hamming distance, the number of changes needed to convert one sequence into another, I wrote this simple implementation:
def HamDist(s,t): return sum([1 for i in range(len (s)) if s[i] != t[i]])
It works and is easily understood. I found this from http://code.activestate.com/recipes/499304-hamming-distance/. I'm not sure I like summing truth values.
from itertools import imap import operator def HamDist(str1, str2): return sum(imap(operator.ne, str1, str2))
I'm learning pretty quickly. There's a lot to learn. I guess once one learns the language the faster code is readable.
Knowing the Hamming distance between a set of DNA, RNA, or AA sequences is the first step to building an un-rooted tree and this is the first step towards reconstructing the most likely ancestor sequences.
Monday, July 22, 2013
I've been sick. I had to take some time off. I'm caught up on Computation Molecular Evolution but am still a week behind on Coding the Matrix. I did a few more Rosalind problems but am currently stumped on one of them. It seems quite simple and I'm sure my answer is correct based upon my understanding of the problem. I've learned a lot about recursive programming in python. I've also learned a bit about markdown. Here's the function Rosalind doesn't accept:
def lev(lex,len,txt=''):
for x in lex.split(' '):
yield txt+x
if len > 1:
for y in lev(lex,len-1,txt+x):
yield y
[x for x in lev('T C A G',3)]
I guess I still need to relearn html so I can set code blocks off more than I've just done.
Friday, July 12, 2013
Names confuse me.
I've gone back and reworked some of my earlier solutions to Rosalind problems. It turned out I lost several of the more complex solutions and all of the tables I had built. Rather than solving my 26th problem I got side traced on mRNA. I'm not sure why I have trouble remembering names like introns, exons, and spliceosomes. Following through Rosalind's links to Wikipedia I learned the codons 'GUG' and 'UUG' can also be start codons but not in humans. When bacteria start with these it is normally translated as formylmethionine rather than their normal Valine and Phenylalinine respectively. I'm having trouble memorizing the names of the various amino acids even though I've been playing FoldIt for years. The two I'm most likely to remember are Proline and Glycine. I remember Proline and Glycine because they are normally part of a loop rather than sheet or helix.
The protein can bend quite freely at Glycine. I should remember Cysteine because they can form a Disulfide Bridge. I think I'll have to mention the amino acids by name for awhile so I can remember their names. Heck, I probably need to do this with the nucleotides as well--It's easy to remember CATG but not so easy to remember Cytosine, Adenine, Thymine, and Guanine. Uracil will need to come along too.
I've never noticed in FoldIt that proteins normally start with Methionine. This is a side-effect
of the start codon AUG being translated, unlike the Stop codons. AUG translates as Methionine.
While I knew the codons weren't one to one with the amino acids I didn't realize just how many codons translated to the same amino and how this alone showed how ridiculous was the claim that even a single mutation would be fatal.
The whole 5' and 3' thing still gives me trouble. We'll see. I wasn't feeling well today so maybe that's causing it. I definitely need to get back to Coursera.
The protein can bend quite freely at Glycine. I should remember Cysteine because they can form a Disulfide Bridge. I think I'll have to mention the amino acids by name for awhile so I can remember their names. Heck, I probably need to do this with the nucleotides as well--It's easy to remember CATG but not so easy to remember Cytosine, Adenine, Thymine, and Guanine. Uracil will need to come along too.
I've never noticed in FoldIt that proteins normally start with Methionine. This is a side-effect
of the start codon AUG being translated, unlike the Stop codons. AUG translates as Methionine.
While I knew the codons weren't one to one with the amino acids I didn't realize just how many codons translated to the same amino and how this alone showed how ridiculous was the claim that even a single mutation would be fatal.
The whole 5' and 3' thing still gives me trouble. We'll see. I wasn't feeling well today so maybe that's causing it. I definitely need to get back to Coursera.
Thursday, July 11, 2013
An evening off
This morning when I woke up I noticed my computer had been rebooted. New windows updates had been installed. Unfortunately I hadn't saved the routines I built for the last few Rosalind problems. I was tired this evening so took a nap. I'm getting ready to go to bed and get a few additional hours sleep before heading off to work.
I spent a few minutes cleaning up some of the earlier solutions such as building the DNA complement. I also started gathering the statistics to build solution to the consensus problem. I'm still not using python comprehensions as must as I probably will in the future. More small steps.
I'm not happy with this temporary solution to building a code block. The ragged right edge doesn't look very pretty. Still it's better than nothing.
You might wonder about why I changed the name of my blog a few weeks ago.
I've started several blogs over the years but, as I said when I change the name, I have a hard time keeping focused on one issue for any length of time. I decided to choose a name that gave me freedom to switch topic as I saw fit. A few years back I got an advertisement saying "Gary Forbis" was a rare name. I found the web page http://gary-forbis.nameanalyzer.net/ that says there were only ten people with that name in the 1990 US census. Since the 1990 census hasn't been released I wonder how they got that information. In 1990 there were two of us working for Washington State. The other one was working as a computer programmer for the transportation department. I was a computer programmer working in Seattle. I saw an obituary for a Gary Forbis who owned a limousine service in Texas. About a year ago I saw another Gary Forbis on google+. That makes two of us on Google+. I don't know how google keeps us separate since we appear to have the same account name. Both of us are programmers and neither of us are the Gary Forbis who worked for the Washington State transportation department. So I know something about 4 of the 10 Gary Forbises in the 1990 census. At least three are computer programmers and two were living in Washington state.
I spent a few minutes cleaning up some of the earlier solutions such as building the DNA complement. I also started gathering the statistics to build solution to the consensus problem. I'm still not using python comprehensions as must as I probably will in the future. More small steps.
def consensus(filename):
clearBioDb()
loadFASTA(filename)
clist=[0 for x in namedSeq[list(namedSeq.keys())[1]]]
counts={x:list(clist) for x in 'ACGT'}
for x in list(namedSeq):
seq=namedSeq[x]
for y in range(seq):
counts[seq[y]][y] +=1
I'm not happy with this temporary solution to building a code block. The ragged right edge doesn't look very pretty. Still it's better than nothing.
You might wonder about why I changed the name of my blog a few weeks ago.
I've started several blogs over the years but, as I said when I change the name, I have a hard time keeping focused on one issue for any length of time. I decided to choose a name that gave me freedom to switch topic as I saw fit. A few years back I got an advertisement saying "Gary Forbis" was a rare name. I found the web page http://gary-forbis.nameanalyzer.net/ that says there were only ten people with that name in the 1990 US census. Since the 1990 census hasn't been released I wonder how they got that information. In 1990 there were two of us working for Washington State. The other one was working as a computer programmer for the transportation department. I was a computer programmer working in Seattle. I saw an obituary for a Gary Forbis who owned a limousine service in Texas. About a year ago I saw another Gary Forbis on google+. That makes two of us on Google+. I don't know how google keeps us separate since we appear to have the same account name. Both of us are programmers and neither of us are the Gary Forbis who worked for the Washington State transportation department. So I know something about 4 of the 10 Gary Forbises in the 1990 census. At least three are computer programmers and two were living in Washington state.
Wednesday, July 10, 2013
Rosland day 7
I guess I'm going to have to learn some key html tags so I can embed code in my blog in a way that sets it apart from normal text. Blobspot only uses a very simple WYSIWYG editor.
I've only solved 19 "problems" but I've learned quite a bit. As I learn more I've quit writing my own code for stuff that is already written. I'm still writing code when I probably don't need to. Also my "old" code isn't the most efficient or elegant. Here's an example from an early Rosalind "problem"
def dna2rna(dna):
#given a string of dna
#return the transcribed
rna=''
for i in range(len(dna)-1):
if dna[i] == 'T': rna = rna+'U'
else: rna = rna+dna[i]
return rna
Little did I know the same thing could be accomplished by:
def dna2rna(dna): return dna.replace('T','U')
These little routines let me find when messenger rna, mRNA, would start coding for a protein.
list(findall(dna2rna(dna),rnaStart))
Again, not much. Still, it's little steps.
The quiz for week three of "Computational Molecular Evolution" had lots of problems. The instructor developed a new quiz. It's pretty short. I think I'll do it tomorrow. I've really got to get started on the "Coding the Matrix" lab.
I've only solved 19 "problems" but I've learned quite a bit. As I learn more I've quit writing my own code for stuff that is already written. I'm still writing code when I probably don't need to. Also my "old" code isn't the most efficient or elegant. Here's an example from an early Rosalind "problem"
def dna2rna(dna):
#given a string of dna
#return the transcribed
rna=''
for i in range(len(dna)-1):
if dna[i] == 'T': rna = rna+'U'
else: rna = rna+dna[i]
return rna
Little did I know the same thing could be accomplished by:
def dna2rna(dna): return dna.replace('T','U')
These little routines let me find when messenger rna, mRNA, would start coding for a protein.
list(findall(dna2rna(dna),rnaStart))
Again, not much. Still, it's little steps.
The quiz for week three of "Computational Molecular Evolution" had lots of problems. The instructor developed a new quiz. It's pretty short. I think I'll do it tomorrow. I've really got to get started on the "Coding the Matrix" lab.
Tuesday, July 9, 2013
Working on Rosalind when I should be working on "Coding the Matrix"
Well, I just became the 1,203 person to solve 16 "problems" on Rosalind. Not much of an accomplishment. I see at least one person solved 32 in only 4 days. Each problem so far has only taken between 5 and 30 minutes. I guess I can be slower than I thought.
I finished the (zero relative) Week 1 lectures in "Coding the Matrix". This weeks lab looks to be interesting. By the end of it I will have defined a vector class with overloaded infix operators.
An infix operator is placed between the two expressions upon which it operates. For instance the plus sign(+) in "4+3" is an infix operator. While a vector can be written as a list, [1, 2, 3, 4] for instance, the class will be using two properties, D and f, for domain and function where given a vector x, x.D is the set of indices in the domain and f is a directory that map indices to their non-zero values. When an index in the domain isn't in the dictionary its value is zero.
In python a dictionary has this form {i:x, j:y, k:z} where the value before the colon(:) is the index and the value after the colon is the value at the index. Given a dictionary f={i:x, j:y, k:z}, f[i] would return the value x.
I've got to go to bed now.
I finished the (zero relative) Week 1 lectures in "Coding the Matrix". This weeks lab looks to be interesting. By the end of it I will have defined a vector class with overloaded infix operators.
An infix operator is placed between the two expressions upon which it operates. For instance the plus sign(+) in "4+3" is an infix operator. While a vector can be written as a list, [1, 2, 3, 4] for instance, the class will be using two properties, D and f, for domain and function where given a vector x, x.D is the set of indices in the domain and f is a directory that map indices to their non-zero values. When an index in the domain isn't in the dictionary its value is zero.
In python a dictionary has this form {i:x, j:y, k:z} where the value before the colon(:) is the index and the value after the colon is the value at the index. Given a dictionary f={i:x, j:y, k:z}, f[i] would return the value x.
I've got to go to bed now.
Monday, July 8, 2013
A day for Coursera
The classes aren't ready until early afternoon my time zone. I made it through "Computational Molecular Evolution" but I hardly started "Coding the Matrix". It didn't really help that CME quizzes had several errors. It's hard enough to learn the material without having the quizzes graded incorrectly. It lead me to question what I was doing. I've learned to take notes from the PAUP quizzes, and this really helped keep me gounded. PAUP is a bioinformatics program written by David L. Swofford. He granted our instructor the right to use the program in our lessons. Since I don't plan on purchasing the product I'll have to learn quite a bit about the methods and terminology. Rosalind seems to be teaching some of it. I don't know how much. This weeks lessons dealt with building trees from pair differences, observed differences between sets of aligned strands of DNA. The same techniques work for proteins.
The "Coding the Matrix" class also had some problems with the popup quizzes during the lectures. I wasn't feeling lucky. Still, I keep learning lots of stuff at a very quick, for me, pace. I'll probably have to spend several evenings to get through the lab.
At least I got my python FASTA format importer to work in only 15 lines of code, including some limited format validation. It looks like lots of people have implemented nearly identical code so there's nothing special here. I'll probably only do a problem every couple of days until I get the Coursera work for the week done.
The "Coding the Matrix" class also had some problems with the popup quizzes during the lectures. I wasn't feeling lucky. Still, I keep learning lots of stuff at a very quick, for me, pace. I'll probably have to spend several evenings to get through the lab.
At least I got my python FASTA format importer to work in only 15 lines of code, including some limited format validation. It looks like lots of people have implemented nearly identical code so there's nothing special here. I'll probably only do a problem every couple of days until I get the Coursera work for the week done.
Sunday, July 7, 2013
Rosalind day 4
I'm not spending much time on this. I've worked through 13 of the "problems". I'm definitely learning python. Today's problems were related to Fibonacci numbers. I'm pretty sure I'll have to use this tomorrow in one of the two Coursera classes I'm currently taking. The Rosalind problems I've solved so far are pretty simple. I've reviewed some of the web pages concerning dynamic programming in python. The example at Math ∩ Programming deals with Fibonacci numbers. I'm not ready to create a complex dynamic solution. I ended up with something like this:
def fib(n):
fibValues = [0,1]
for i in range(2,n+1):
fibValues.append(fibValues[i-1] + fibValues[i-2])
return fibValues[n]
rather than something like this:
def memoize(f):
cache = {}
def memoizedFunction(*args):
if args not in cache:
cache[args] = f(*args)
return cache[args]
memoizedFunction.cache = cache
return memoizedFunction
@memoize
def fib(n):
if n <= 2:
return 1
else:
return fib(n-1) + fib(n-2)
It doesn't matter that the latter is a more elegant solution. I'm just glad my solution was nearly identical to other people's solutions.
def fib(n):
fibValues = [0,1]
for i in range(2,n+1):
fibValues.append(fibValues[i-1] + fibValues[i-2])
return fibValues[n]
rather than something like this:
def memoize(f):
cache = {}
def memoizedFunction(*args):
if args not in cache:
cache[args] = f(*args)
return cache[args]
memoizedFunction.cache = cache
return memoizedFunction
@memoize
def fib(n):
if n <= 2:
return 1
else:
return fib(n-1) + fib(n-2)
It doesn't matter that the latter is a more elegant solution. I'm just glad my solution was nearly identical to other people's solutions.
Thursday, July 4, 2013
On learning Python and more
Well, I've finished Rosalind's Python Village. It was pretty easy. It didn't go into much depth. I've learned more about reading and writing files. This complements my first "Coding the Matrix" lesson.
It appears Rosalind will now track more with my "Computational Molecular Evolution" course than with "Coding the Matrix", at least for now.
I'm near my limits right now. It's going to be hard to track and remember all of this stuff. I'll try to figure out how to format the additional pages. I don't particularly want to create separate pages as one big blob. I'd like to put the gadgets on the secondary pages rather than all on the front page. I'll do now and fix later, or rather I'm running out of steam for this evening, I'll do tomorrow night and fix later.
I don't think I'll have much time for foldit for awhile. I'm down to just getting some points on each puzzle. I'm guessing the courses will help me with protein alignments. Here's hoping.
It appears Rosalind will now track more with my "Computational Molecular Evolution" course than with "Coding the Matrix", at least for now.
I'm near my limits right now. It's going to be hard to track and remember all of this stuff. I'll try to figure out how to format the additional pages. I don't particularly want to create separate pages as one big blob. I'd like to put the gadgets on the secondary pages rather than all on the front page. I'll do now and fix later, or rather I'm running out of steam for this evening, I'll do tomorrow night and fix later.
I don't think I'll have much time for foldit for awhile. I'm down to just getting some points on each puzzle. I'm guessing the courses will help me with protein alignments. Here's hoping.
Tuesday, July 2, 2013
A new beginning
OK, I've changed my focus yet again. I don't seem able to keep my attention on one area for very long. I keep coming back to the same topics.
I'll drop my musings on economic issues for now and chronicle what I've been learning most recently.
I finished the Coursera class, "Synapse, Neurons, and Brains" about a month ago. It covered a lot of material, none in any real depth. I had to learn a few electronic formula and concepts. There were no lab work; all I did was watch the lectures and take the tests. I'll expand my knowledge as I get up to speed in other areas. For now I'll set this aside then come back to neural network models later. NEURON is an open source implementation of Rall's Cable Theory, http://en.wikipedia.org/wiki/Cable_theory. I don't have the computing power to do much right now. The Blue Brain project, http://bluebrain.epfl.ch/, is using a 16k core supercomputer to simulate about 10k neurons. Just getting up to speed and expanding my knowledge about how to program these things simply will be my focus for now. Actual discovery will have to wait.
I'm in the second week of "Computation Molecular Evolution". This class covered the evolution theory basics and population frequencies in the first week and dealt with phylogenetic trees and some tools to help analyze them in the second week.
I started "Coding the Matrix" this week. It looks to be quite time intensive but should teach me a lot of new tricks and methods. The class lab work runs on a virtual machine under Oracle's VirturalBox using a disk image of an Umbutu
Many of the comments in the forums for these three classes mentioned edX and Rosalind. edX is much like Coursera in that one can take college level courses on line for free. I hope this model is sustainable. I may take courses from both and elsewhere. Rosalind focuses on Bioinformatics. I've started Rosalind. I'll back away for a few days while I verify I can handle both 2.x and 3.x versions of Python. I might have to just use two computers. I considered installing a Win7 virtual machine using Oracle's VirtualBox. I've backed away from that idea. I have enough on my plate.
I'll drop my musings on economic issues for now and chronicle what I've been learning most recently.
I finished the Coursera class, "Synapse, Neurons, and Brains" about a month ago. It covered a lot of material, none in any real depth. I had to learn a few electronic formula and concepts. There were no lab work; all I did was watch the lectures and take the tests. I'll expand my knowledge as I get up to speed in other areas. For now I'll set this aside then come back to neural network models later. NEURON is an open source implementation of Rall's Cable Theory, http://en.wikipedia.org/wiki/Cable_theory. I don't have the computing power to do much right now. The Blue Brain project, http://bluebrain.epfl.ch/, is using a 16k core supercomputer to simulate about 10k neurons. Just getting up to speed and expanding my knowledge about how to program these things simply will be my focus for now. Actual discovery will have to wait.
I'm in the second week of "Computation Molecular Evolution". This class covered the evolution theory basics and population frequencies in the first week and dealt with phylogenetic trees and some tools to help analyze them in the second week.
I started "Coding the Matrix" this week. It looks to be quite time intensive but should teach me a lot of new tricks and methods. The class lab work runs on a virtual machine under Oracle's VirturalBox using a disk image of an Umbutu
Many of the comments in the forums for these three classes mentioned edX and Rosalind. edX is much like Coursera in that one can take college level courses on line for free. I hope this model is sustainable. I may take courses from both and elsewhere. Rosalind focuses on Bioinformatics. I've started Rosalind. I'll back away for a few days while I verify I can handle both 2.x and 3.x versions of Python. I might have to just use two computers. I considered installing a Win7 virtual machine using Oracle's VirtualBox. I've backed away from that idea. I have enough on my plate.
Wednesday, February 27, 2013
I was reviewing the OECD web site. It claims income taxes add friction to economic activities. I think it does but not for the reason stated. If two companies produce the same goods but one produces the goods more efficiently the one that produces the goods more efficiently will pay more taxes. The same is true of a value added tax. It isn't that the tax burden changes one's behavior; it's that unequally applied taxes affect choices.
Governments need revenues to fund their activities. The important part to remember when trying to craft a system that helps the most people to a better life is that a government that wants to help the majority will favor tax and spending policies that favor economic choices whose effect improves the lives of their citizens.
Governments need revenues to fund their activities. The important part to remember when trying to craft a system that helps the most people to a better life is that a government that wants to help the majority will favor tax and spending policies that favor economic choices whose effect improves the lives of their citizens.
Sunday, February 24, 2013
When people don't have expendable income they can't send the economic signals necessary to inform producers. I don't know if there is an economic stable state where everyone has a living wage but we need to look hard for one. We might need to adjust tax laws to make it happen. Some care about what is fair and just. I care about outcome. We can deal with fairness later.
Most of us earn our living through our labor. We don't have the savings to survive very long without a paycheck. This puts a downward pressure on the labor market since we have to settle so we can survive.
Retirees have been moved from defined benefit plans to defined contribution plans. Retirees have to schedule dividends and interest sufficiently to provide living income or they have to sell some of their capital. If they have to sell capital they have to settle on the price when they need to make the sale and this puts a downward pressure on capital assets
Only those who don't need to make a trade can wait for the markets to come to them. They don't need to settle or either a buy or a sell so they can use a strategy to their advantage. They can even play games with the market to their advantage.
What we are seeing in the US is the end game of unequal power. Our economy is grinding to a halt as a smaller and smaller portion of the population has an ever increasing percentage of the nation's wealth. We have to change the dynamics so these people have to make trades at least as urgently as those beneath them. We don't need to be confiscatory and shouldn't want to be. We merely need to adjust the conditions of the trade where the very wealthy isn't getting as great of growth as the economy. The excess growth should be distributed most heavily to the poor then trailing off up the wealth scale. The rate of growth should help inform us.
Most of us earn our living through our labor. We don't have the savings to survive very long without a paycheck. This puts a downward pressure on the labor market since we have to settle so we can survive.
Retirees have been moved from defined benefit plans to defined contribution plans. Retirees have to schedule dividends and interest sufficiently to provide living income or they have to sell some of their capital. If they have to sell capital they have to settle on the price when they need to make the sale and this puts a downward pressure on capital assets
Only those who don't need to make a trade can wait for the markets to come to them. They don't need to settle or either a buy or a sell so they can use a strategy to their advantage. They can even play games with the market to their advantage.
What we are seeing in the US is the end game of unequal power. Our economy is grinding to a halt as a smaller and smaller portion of the population has an ever increasing percentage of the nation's wealth. We have to change the dynamics so these people have to make trades at least as urgently as those beneath them. We don't need to be confiscatory and shouldn't want to be. We merely need to adjust the conditions of the trade where the very wealthy isn't getting as great of growth as the economy. The excess growth should be distributed most heavily to the poor then trailing off up the wealth scale. The rate of growth should help inform us.
Saturday, February 23, 2013
Economics is the study of the distribution of scarce resources. When you hear, or read, "scarce resource" you might think of gold, silver, and other rare metals but the concept is more general than that. From Scarce Resource the definition is a resource whose availability is less than its desired use. The concept can be apply to potable water, clay, and even hours in the day.
In the United States we use market capitalism to distribute some scarce resources, goods, and services. The idea is deciding how to distribute scarce goods and services is too complex to calculate but the markets closely approximates the best distribution by allowing people to make their own choices about which items they would rather have. We hold the individuals feel themselves better off after a trade in a free market than they were before the trade. Why would people trade things they think more valuable to themselves for things they think are less valuable?
Not all scarcity can be resolved through markets. For instance there are only so many nice summer days in a year. I know I would like more but I'm not going to get more than there are no matter how much I would be willing to spend for them. Sure, I can schedule my vacations at times when it is more likely to be a nice summer day so I can fully experience them but I can't produce them on demand.
So there are the economic concepts of public goods and private goods. The main distinction is private goods are excludable however public goods are also non-rivalrous. We focus on excludability because we are using market capitalism to distribute goods and there's no way to make a market when goods are not excludable. I want to focus on non-rivalrous goods.
While some websites require subscription for access most of the websites we reference every day are basically free for us. As long as the sufficient bandwidth we can think of them as non-rivalrous because my consumption doesn't (significantly) reduce your ability to consume them.
One of the major problems with market capitalism is the monitization of demand. Even though all of us have some shared basic needs such as food, clothing, shelter, etc. The monitization of demand means the desires of the wealth can overshadow the needs of the poor in the markets. The markets are signaled by the effective demand produced by money.
If we want to create a better life for all we need to increase the market signals for goods and services needed by people and focus our production and consumption of goods and services beyond our needs on non-rivalrous goods. We can still consume rivalrous goods but we should try to consume the least scarce of them for private gain and use the most scarce in producing the greatest good for the most.
In the United States we use market capitalism to distribute some scarce resources, goods, and services. The idea is deciding how to distribute scarce goods and services is too complex to calculate but the markets closely approximates the best distribution by allowing people to make their own choices about which items they would rather have. We hold the individuals feel themselves better off after a trade in a free market than they were before the trade. Why would people trade things they think more valuable to themselves for things they think are less valuable?
Not all scarcity can be resolved through markets. For instance there are only so many nice summer days in a year. I know I would like more but I'm not going to get more than there are no matter how much I would be willing to spend for them. Sure, I can schedule my vacations at times when it is more likely to be a nice summer day so I can fully experience them but I can't produce them on demand.
So there are the economic concepts of public goods and private goods. The main distinction is private goods are excludable however public goods are also non-rivalrous. We focus on excludability because we are using market capitalism to distribute goods and there's no way to make a market when goods are not excludable. I want to focus on non-rivalrous goods.
While some websites require subscription for access most of the websites we reference every day are basically free for us. As long as the sufficient bandwidth we can think of them as non-rivalrous because my consumption doesn't (significantly) reduce your ability to consume them.
One of the major problems with market capitalism is the monitization of demand. Even though all of us have some shared basic needs such as food, clothing, shelter, etc. The monitization of demand means the desires of the wealth can overshadow the needs of the poor in the markets. The markets are signaled by the effective demand produced by money.
If we want to create a better life for all we need to increase the market signals for goods and services needed by people and focus our production and consumption of goods and services beyond our needs on non-rivalrous goods. We can still consume rivalrous goods but we should try to consume the least scarce of them for private gain and use the most scarce in producing the greatest good for the most.
Thursday, February 21, 2013
On the way to work yesterday I talked with a guy who was a "sanitation engineer" but by description of his work, a janitor. We got to talking about how he turned his life around through Christ. Being an atheist(agnostic with a predisposition to disbelieve) I wasn't so concerned by that but by our life differences and similarities.
My talents let me learn many new and complex tasks quickly. I don't do well in a university setting but I can pick up a book or follow some one doing a job and do it. Being able to learn quickly gives me some advantages over most people in the labor force and consequentially I'm pretty well paid.
Many of the people in my circle of friends and relatives make comments about how I deserve my higher pay. They say people who settle on janitor or store clerk or lawn care or any of many other jobs just don't deserve as much and besides the market sets people's wages. Don't get me wrong, I like having money left over at the end of the month and not having to worry about a bit of splurging; I just don't know why I deserve more than other hard working people.
The problem is I feel I deserve some benefit for what I bring to the table even if others work a bit harder than I. My talents provide benefits not just for me. Others gain from me using my talents. Why shouldn't I be compensated for what I bring to the table?
So here we are. Some people work hard and get nowhere while others work less hard and accomplish a lot. I have no desire to work hard so people who don't bring my talents to the table and don't work hard can bum around but I would really like people who put in the effort to benefit from the surplus of goods and services the community of us can provide. Specialization provides benefits for all. There are jobs I don't like doing and jobs others can't do. OK, most people don't like doing jobs I don't like doing, I get it, but they need to be done and what do I get in return for sharing the benefits of my talents and hard work? Aren't we equals?
Somehow we have to find a way where everyone helps out and people only have to do the minimum of what they don't like doing. The labor markets are broken because some of us come to the table with more power than others even when we want to give everyone a fair shake. I don't want to abuse you and I don't want you abusing me. I want a fair trade for both our benefits.
My talents let me learn many new and complex tasks quickly. I don't do well in a university setting but I can pick up a book or follow some one doing a job and do it. Being able to learn quickly gives me some advantages over most people in the labor force and consequentially I'm pretty well paid.
Many of the people in my circle of friends and relatives make comments about how I deserve my higher pay. They say people who settle on janitor or store clerk or lawn care or any of many other jobs just don't deserve as much and besides the market sets people's wages. Don't get me wrong, I like having money left over at the end of the month and not having to worry about a bit of splurging; I just don't know why I deserve more than other hard working people.
The problem is I feel I deserve some benefit for what I bring to the table even if others work a bit harder than I. My talents provide benefits not just for me. Others gain from me using my talents. Why shouldn't I be compensated for what I bring to the table?
So here we are. Some people work hard and get nowhere while others work less hard and accomplish a lot. I have no desire to work hard so people who don't bring my talents to the table and don't work hard can bum around but I would really like people who put in the effort to benefit from the surplus of goods and services the community of us can provide. Specialization provides benefits for all. There are jobs I don't like doing and jobs others can't do. OK, most people don't like doing jobs I don't like doing, I get it, but they need to be done and what do I get in return for sharing the benefits of my talents and hard work? Aren't we equals?
Somehow we have to find a way where everyone helps out and people only have to do the minimum of what they don't like doing. The labor markets are broken because some of us come to the table with more power than others even when we want to give everyone a fair shake. I don't want to abuse you and I don't want you abusing me. I want a fair trade for both our benefits.
Tuesday, February 19, 2013
During the day I realized just how perverse our system has become.
We have moved from defined benefit retirement plans to defined contribution retirement plans. Sure defined benefit plans weren't always working the way they should--many plans went under and had to be picked up by the PBGC who reduce scheduled payments to the retirees--but a defined contribution plan leaves future retirees wondering if they've saved enough to retire. Most haven't.
Most of us have a hard enough time getting our work done and having some time for ourselves. We aren't trained to properly invest for retirement and don't have the time even if we are. This makes us easy marks with lots of cash we aren't using right now. We won't know if our "investments" have paid off until we try to retire on them.
Costs get pushed down the food chain. While investments needn't be a zero-sum game most retirement investments are done in aftermarket transfers. This means the money we use to buy a stock isn't increasing the investment dollars available to the company whose stock we buy but into the hands of the prior investor who sold the stock. It's a zero-sum game as far as the company is concerned. Those who have the time to make more informed decisions will win over those who don't have the time or skill to do so. The effect is a concentration of wealth in the hands of those who can play the game from those who are just trying to prepare for their retirement.
We have moved from defined benefit retirement plans to defined contribution retirement plans. Sure defined benefit plans weren't always working the way they should--many plans went under and had to be picked up by the PBGC who reduce scheduled payments to the retirees--but a defined contribution plan leaves future retirees wondering if they've saved enough to retire. Most haven't.
Most of us have a hard enough time getting our work done and having some time for ourselves. We aren't trained to properly invest for retirement and don't have the time even if we are. This makes us easy marks with lots of cash we aren't using right now. We won't know if our "investments" have paid off until we try to retire on them.
Costs get pushed down the food chain. While investments needn't be a zero-sum game most retirement investments are done in aftermarket transfers. This means the money we use to buy a stock isn't increasing the investment dollars available to the company whose stock we buy but into the hands of the prior investor who sold the stock. It's a zero-sum game as far as the company is concerned. Those who have the time to make more informed decisions will win over those who don't have the time or skill to do so. The effect is a concentration of wealth in the hands of those who can play the game from those who are just trying to prepare for their retirement.
This morning I was able to clear my mind a bit about how we compensate people. It turns out we are using desperation to get the worst jobs done. Sure many jobs are unskilled or low skilled but there is always some skills needed and some talents. Instead of paying more for jobs we don't want to do and don't like doing we rely upon people getting hungry enough to do these jobs. As long as we keep a ready supply of hungry people around these jobs will get done.
How can it be moral to rely upon desperation to get people to do things they wouldn't otherwise do?
It seems to me that we need to figure out how to support a minimum stipend so people don't feel forced to take a job then we need to let the market forces drive the wage up for jobs no one wants to do but need to be done.
How can it be moral to rely upon desperation to get people to do things they wouldn't otherwise do?
It seems to me that we need to figure out how to support a minimum stipend so people don't feel forced to take a job then we need to let the market forces drive the wage up for jobs no one wants to do but need to be done.
Subscribe to:
Posts (Atom)